Analyzing Bike Sharing Demand
Recently, I worked on an assignment to analyze the data from bikesharing system to predict its demand. In this post, we will see how the given data can be analyzed using statistical machine learning methods.
The original dataset can be found here on Kaggle.
https://www.kaggle.com/c/bike-sharing-demand
In this notebook, we would be using a small subset of this dataset and just focus on the methodology. The accuracies can’t be expected to be high for such a small subset of the dataset. Feel free to use the complete dataset for your analysis.
You can download the CSV data used in this noteboot from Google drive.
https://drive.google.com/file/d/1GWbrrsPe6B-0ZKn4Dxd7D8pNvfK6IsQZ/view?usp=sharing
season month holiday day_of_week ... atemp humidity windspeed count
0 Spring May 0 Tue ... 26.0 76.5833 0.118167 6073.0
1 Fall Dec 0 Tue ... 19.0 73.3750 0.174129 6606.0
2 Spring Jun 0 Thu ... 28.0 56.9583 0.253733 7363.0
3 Fall Dec 0 Sun ... 4.0 58.6250 0.169779 2431.0
4 Summer Sep 0 Wed ... 23.0 91.7083 0.097021 1996.0
[5 rows x 11 columns]
Data Exploration
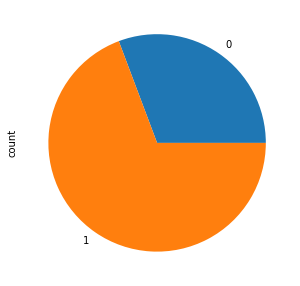
Bikeshares for weekend vs weekdays
The plot uses the workingday column to get information about weekday or weekend. Clearly lot more bikeshares happen on weekdays as compared to weekends.
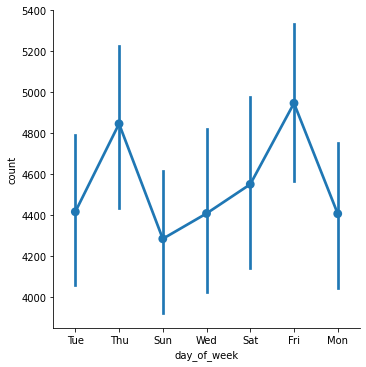
Also, on a more detailed level the factor plot is plotted to see the variations in bikeshares based on the day of the week.
The factor plot reaffirms our observation from the pie chart and tells us that during weekends Sunday sees the least number of bikeshares.
Bikeshares during different weather conditions
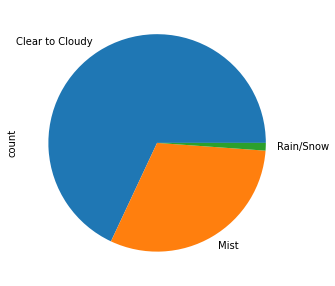
The plot below shows that most bikeshares happen when the weather is clear to cloudy. People also seem to be using bikeshares in misty weather conditions. Quite intuitively, the number of bikeshares on a rainy or snowy day is quite less.
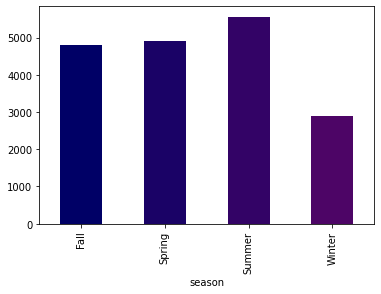
Bikeshares during different seasons
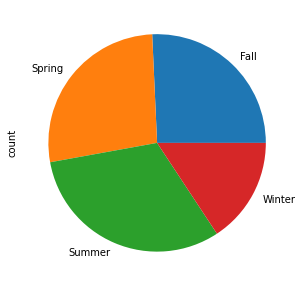
Firstly a pie chart is plotted for visualizing the number of bikeshares in different seasons. The pie chart doesn’t provide a clear picture so next a bar chart is used to get a clearer picture.
The bar chart shows that most bikeshares happen during Summer while Winter accounts for the least number of bikeshares.
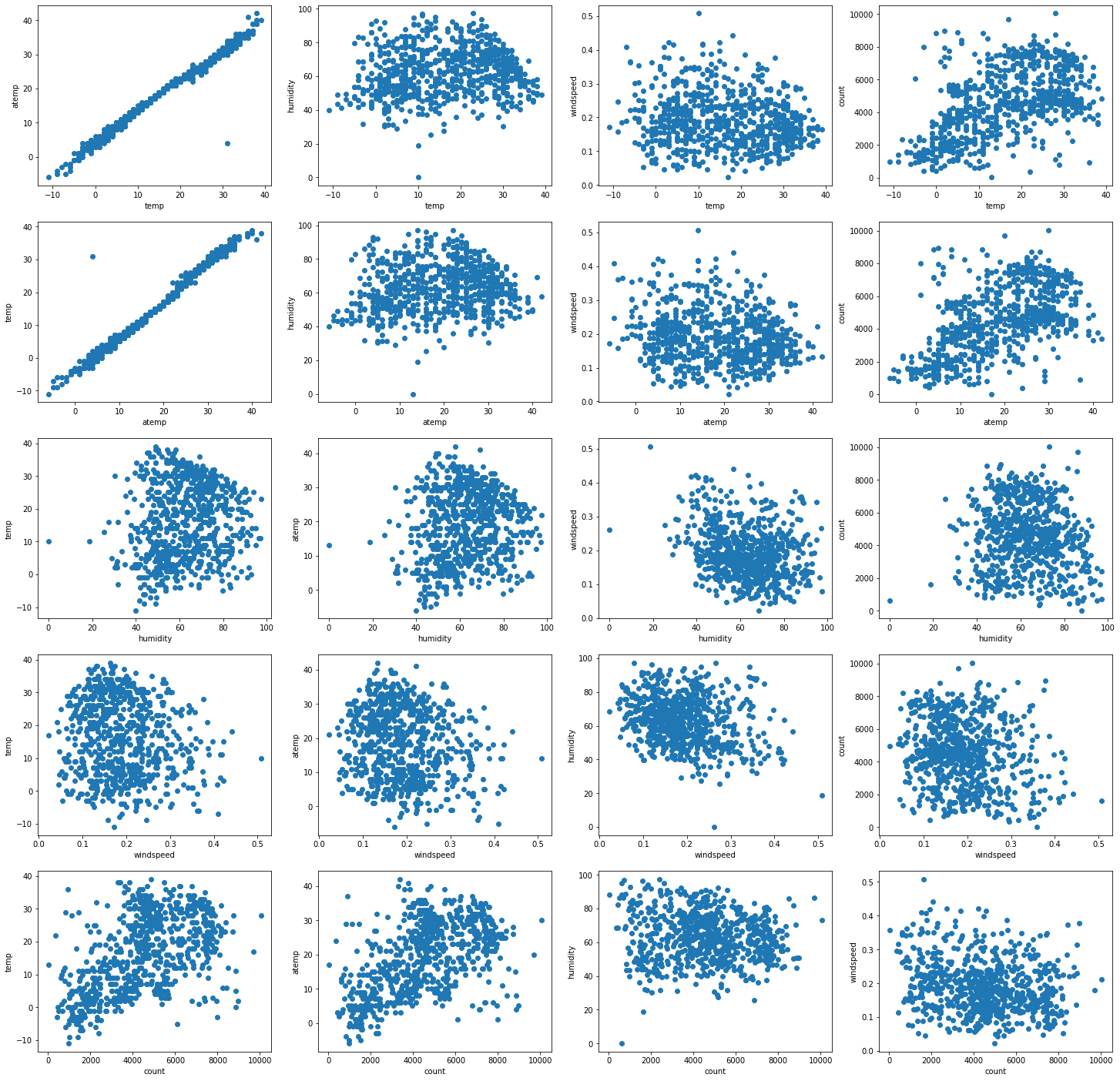
Exploring linear non-linear dependencies
As it is apparent from the plots below, some of the variables have linear dependencies with others while some don’t have a linear relationship.
| Variable | Linear | Inverse-linear | Non-Linear |
|---|---|---|---|
| Temp | atemp, count | - | humidity, windspeed |
| atemp | temp, count | - | humidity, windspeed |
| humidity | - | windspeed | temp, atemp, count |
| windspeed | - | humidity | temp, atemp, count |
| count | temp, atemp | - | humidity, windspeed |
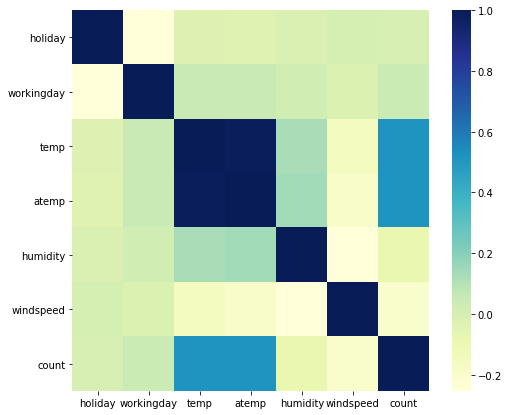
Moreover, lets find the correlation between the variables to further analyse the dependencies between variables.
In the correlation heatmap, the blue shades represent higher level of correlation between the variables.
Note: temp, atemp variables show good amount of positive correlation with count.
Index(['season', 'month', 'holiday', 'day_of_week', 'workingday', 'weather',
'temp', 'atemp', 'humidity', 'windspeed', 'count'],
dtype='object')
Should polynomial transformation be performed?
Clearly not all features exhibit a linear dependency with the predictor variable ie. count so it might be worthwhile to try a polynomial transformation and visualize the dependencies again.
Before that lets do some more data exploration to further improve the data for linear regression.
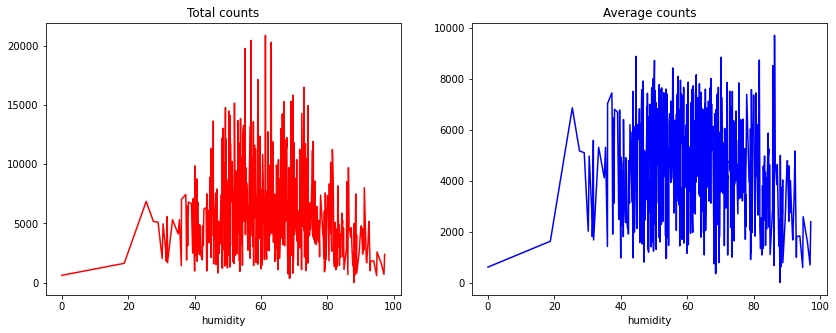
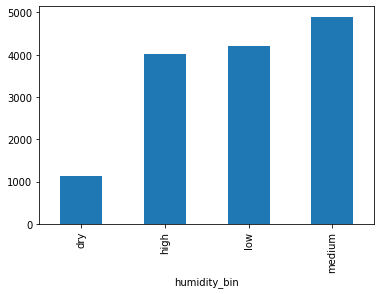
Bikeshares sum and mean plots grouped based on humidity
The idea is to see the variations in bikeshares for different humidity levels and then bin the values into multiple groups.
Text(0.5, 1.0, 'Average counts')
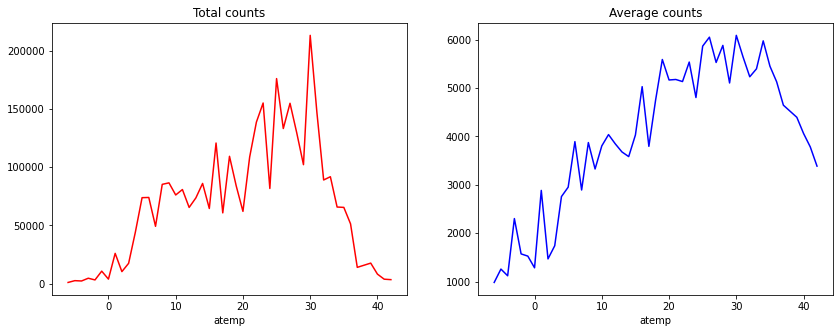
Bikeshares sum and mean plots grouped based on atemp
Similar to humidity, the idea is to see the variations in bikeshares for different atemp levels and then bin the values into multiple groups.
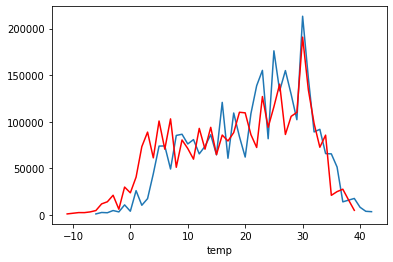
Moreover, temp and atemp is compared to see how these values vary.
Text(0.5, 1.0, 'Average counts')
| temp | temp_no | |
|---|---|---|
| 0 | 24.0 | 37.0 |
| 1 | 15.0 | 20.0 |
| 2 | 26.0 | 48.0 |
| 3 | 0.0 | 12.0 |
| 4 | 23.0 | 46.0 |
| ... | ... | ... |
| 726 | 26.0 | 48.0 |
| 727 | 33.0 | 25.0 |
| 728 | 30.0 | 49.0 |
| 729 | 8.0 | 17.0 |
| 730 | 16.0 | 30.0 |
731 rows × 2 columns
<matplotlib.axes._subplots.AxesSubplot at 0x7fe857347240>
| season | month | holiday | day_of_week | workingday | weather | temp | atemp | windspeed | count | temp_no | atemp_bin_cold | atemp_bin_mild | atemp_bin_warm | humidity_bin_low | humidity_bin_medium | humidity_bin_high | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Spring | May | 0 | Tue | 1 | Mist | 24.0 | 26.0 | 0.118167 | 6073.0 | 37.0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | Fall | Dec | 0 | Tue | 1 | Clear to Cloudy | 15.0 | 19.0 | 0.174129 | 6606.0 | 20.0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 2 | Spring | Jun | 0 | Thu | 1 | Clear to Cloudy | 26.0 | 28.0 | 0.253733 | 7363.0 | 48.0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 3 | Fall | Dec | 0 | Sun | 0 | Clear to Cloudy | 0.0 | 4.0 | 0.169779 | 2431.0 | 12.0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | Summer | Sep | 0 | Wed | 1 | Rain/Snow | 23.0 | 23.0 | 0.097021 | 1996.0 | 46.0 | 0 | 1 | 0 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 726 | Summer | Sep | 0 | Fri | 1 | Mist | 26.0 | 27.0 | 0.139929 | 4727.0 | 48.0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 727 | Summer | Aug | 0 | Wed | 1 | Clear to Cloudy | 33.0 | 32.0 | 0.200258 | 4780.0 | 25.0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 728 | Summer | Sep | 0 | Sun | 0 | Clear to Cloudy | 30.0 | 31.0 | 0.206467 | 4940.0 | 49.0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 729 | Winter | Jan | 0 | Sun | 0 | Clear to Cloudy | 8.0 | 13.0 | 0.192167 | 2294.0 | 17.0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 730 | Spring | Apr | 0 | Thu | 1 | Clear to Cloudy | 16.0 | 20.0 | 0.065929 | 6565.0 | 30.0 | 0 | 1 | 0 | 0 | 1 | 0 |
731 rows × 17 columns
Encoding categorical variables
month holiday ... weather_Mist weather_Rain/Snow
0 8 0 ... 1 0
1 2 0 ... 0 0
2 6 0 ... 0 0
3 2 0 ... 0 0
4 11 0 ... 0 1
[5 rows x 22 columns]
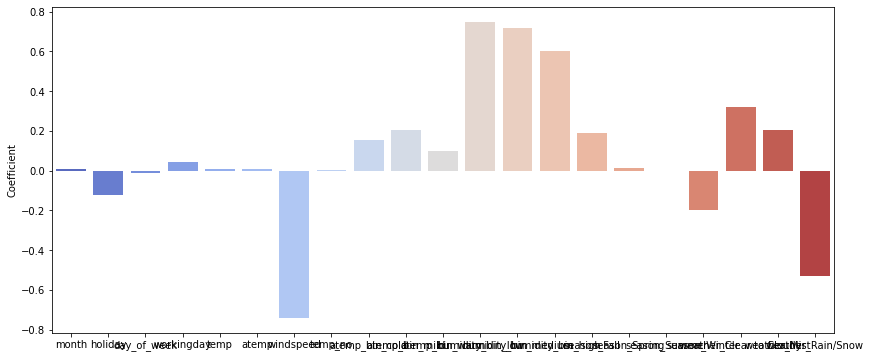
Checking for positive/negative correlation & statisitical significance
Some of the variables have negative correlation like windspeed, atemp_bin_cold, humidity_bin_high, season_Winter, weather_Mist, weather_Rain/Snow. Other variables with -ve sign have a very low -ve value and can be safely ignored.
Similarly, the table shows variables with positive correlation.
------ Positive/negative correlation with predictor variable(count) --------
month 0.186275
holiday -0.004103
day_of_week -0.045716
workingday 0.042159
temp 0.516475
atemp 0.516624
windspeed -0.195128
count 1.000000
temp_no 0.429402
atemp_bin_cold -0.225357
atemp_bin_mild 0.388137
atemp_bin_warm 0.161776
humidity_bin_low -0.076209
humidity_bin_medium 0.201935
humidity_bin_high -0.153773
season_Fall 0.071844
season_Spring 0.101960
season_Summer 0.294050
season_Winter -0.471729
weather_Clear to Cloudy 0.219172
weather_Mist -0.140658
weather_Rain/Snow -0.233985
Name: count, dtype: float64
------------------------------
Statistical significance
Statistical significance can be measured using P-values.
- more the number of *(stars) and higher the value, the statistical significance would be higher.
Note: Statistical significance assumes linear dependencies.
| month | holiday | day_of_week | workingday | temp | atemp | windspeed | count | temp_no | atemp_bin_cold | atemp_bin_mild | atemp_bin_warm | humidity_bin_low | humidity_bin_medium | humidity_bin_high | season_Fall | season_Spring | season_Summer | season_Winter | weather_Clear to Cloudy | weather_Mist | weather_Rain/Snow | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month | 1.0*** | 0.02 | 0.01 | -0.01 | 0.11*** | 0.12*** | -0.12*** | 0.19*** | 0.15*** | -0.08** | 0.29*** | -0.12*** | -0.16*** | 0.03 | 0.1*** | 0.4*** | -0.11*** | -0.05 | -0.23*** | -0.04 | 0.01 | 0.06* |
| holiday | 0.02 | 1.0*** | -0.12*** | -0.25*** | -0.03 | -0.03 | 0.01 | -0.0 | -0.02 | 0.02 | -0.07* | 0.05 | -0.03 | 0.03 | -0.01 | 0.02 | -0.02 | -0.03 | 0.03 | 0.03 | -0.02 | -0.03 |
| day_of_week | 0.01 | -0.12*** | 1.0*** | 0.2*** | 0.03 | 0.03 | 0.0 | -0.05 | 0.01 | 0.01 | 0.0 | 0.03 | 0.02 | -0.03 | 0.02 | 0.0 | 0.0 | 0.01 | -0.01 | -0.0 | -0.03 | 0.1*** |
| workingday | -0.01 | -0.25*** | 0.2*** | 1.0*** | 0.05 | 0.05 | -0.02 | 0.04 | 0.05 | -0.02 | 0.06 | 0.01 | -0.03 | 0.05 | -0.02 | -0.01 | 0.01 | 0.02 | -0.03 | -0.06 | 0.05 | 0.03 |
| temp | 0.11*** | -0.03 | 0.03 | 0.05 | 1.0*** | 0.99*** | -0.16*** | 0.52*** | 0.55*** | -0.47*** | 0.47*** | 0.58*** | -0.15*** | 0.11*** | 0.01 | -0.22*** | 0.16*** | 0.68*** | -0.62*** | 0.12*** | -0.1*** | -0.06 |
| atemp | 0.12*** | -0.03 | 0.03 | 0.05 | 0.99*** | 1.0*** | -0.18*** | 0.52*** | 0.54*** | -0.44*** | 0.47*** | 0.58*** | -0.17*** | 0.12*** | 0.01 | -0.21*** | 0.16*** | 0.66*** | -0.62*** | 0.11*** | -0.09** | -0.07* |
| windspeed | -0.12*** | 0.01 | 0.0 | -0.02 | -0.16*** | -0.18*** | 1.0*** | -0.2*** | -0.13*** | 0.09** | -0.1*** | -0.11*** | 0.28*** | -0.13*** | -0.1*** | -0.14*** | 0.1*** | -0.14*** | 0.18*** | -0.0 | -0.04 | 0.12*** |
| count | 0.19*** | -0.0 | -0.05 | 0.04 | 0.52*** | 0.52*** | -0.2*** | 1.0*** | 0.43*** | -0.23*** | 0.39*** | 0.16*** | -0.08** | 0.2*** | -0.15*** | 0.07* | 0.1*** | 0.29*** | -0.47*** | 0.22*** | -0.14*** | -0.23*** |
| temp_no | 0.15*** | -0.02 | 0.01 | 0.05 | 0.55*** | 0.54*** | -0.13*** | 0.43*** | 1.0*** | -0.17*** | 0.5*** | 0.07* | -0.16*** | 0.03 | 0.11*** | -0.03 | 0.19*** | 0.29*** | -0.45*** | 0.01 | 0.0 | -0.03 |
| atemp_bin_cold | -0.08** | 0.02 | 0.01 | -0.02 | -0.47*** | -0.44*** | 0.09** | -0.23*** | -0.17*** | 1.0*** | -0.55*** | -0.29*** | -0.01 | -0.03 | 0.04 | 0.34*** | -0.08** | -0.41*** | 0.16*** | -0.1*** | 0.09** | 0.03 |
| atemp_bin_mild | 0.29*** | -0.07* | 0.0 | 0.06 | 0.47*** | 0.47*** | -0.1*** | 0.39*** | 0.5*** | -0.55*** | 1.0*** | -0.32*** | -0.1*** | -0.03 | 0.12*** | -0.08** | 0.31*** | 0.15*** | -0.38*** | -0.0 | 0.01 | -0.02 |
| atemp_bin_warm | -0.12*** | 0.05 | 0.03 | 0.01 | 0.58*** | 0.58*** | -0.11*** | 0.16*** | 0.07* | -0.29*** | -0.32*** | 1.0*** | -0.06 | 0.16*** | -0.13*** | -0.23*** | -0.13*** | 0.58*** | -0.23*** | 0.15*** | -0.13*** | -0.07* |
| humidity_bin_low | -0.16*** | -0.03 | 0.02 | -0.03 | -0.15*** | -0.17*** | 0.28*** | -0.08** | -0.16*** | -0.01 | -0.1*** | -0.06 | 1.0*** | -0.51*** | -0.25*** | -0.15*** | 0.08** | -0.07* | 0.14*** | 0.3*** | -0.28*** | -0.07** |
| humidity_bin_medium | 0.03 | 0.03 | -0.03 | 0.05 | 0.11*** | 0.12*** | -0.13*** | 0.2*** | 0.03 | -0.03 | -0.03 | 0.16*** | -0.51*** | 1.0*** | -0.69*** | 0.07** | -0.12*** | 0.11*** | -0.06* | 0.24*** | -0.17*** | -0.2*** |
| humidity_bin_high | 0.1*** | -0.01 | 0.02 | -0.02 | 0.01 | 0.01 | -0.1*** | -0.15*** | 0.11*** | 0.04 | 0.12*** | -0.13*** | -0.25*** | -0.69*** | 1.0*** | 0.05 | 0.08** | -0.07* | -0.06 | -0.52*** | 0.43*** | 0.27*** |
| season_Fall | 0.4*** | 0.02 | 0.0 | -0.01 | -0.22*** | -0.21*** | -0.14*** | 0.07* | -0.03 | 0.34*** | -0.08** | -0.23*** | -0.15*** | 0.07** | 0.05 | 1.0*** | -0.33*** | -0.33*** | -0.33*** | -0.06* | 0.03 | 0.09** |
| season_Spring | -0.11*** | -0.02 | 0.0 | 0.01 | 0.16*** | 0.16*** | 0.1*** | 0.1*** | 0.19*** | -0.08** | 0.31*** | -0.13*** | 0.08** | -0.12*** | 0.08** | -0.33*** | 1.0*** | -0.34*** | -0.33*** | -0.02 | 0.04 | -0.04 |
| season_Summer | -0.05 | -0.03 | 0.01 | 0.02 | 0.68*** | 0.66*** | -0.14*** | 0.29*** | 0.29*** | -0.41*** | 0.15*** | 0.58*** | -0.07* | 0.11*** | -0.07* | -0.33*** | -0.34*** | 1.0*** | -0.34*** | 0.11*** | -0.1*** | -0.03 |
| season_Winter | -0.23*** | 0.03 | -0.01 | -0.03 | -0.62*** | -0.62*** | 0.18*** | -0.47*** | -0.45*** | 0.16*** | -0.38*** | -0.23*** | 0.14*** | -0.06* | -0.06 | -0.33*** | -0.33*** | -0.34*** | 1.0*** | -0.02 | 0.03 | -0.02 |
| weather_Clear to Cloudy | -0.04 | 0.03 | -0.0 | -0.06 | 0.12*** | 0.11*** | -0.0 | 0.22*** | 0.01 | -0.1*** | -0.0 | 0.15*** | 0.3*** | 0.24*** | -0.52*** | -0.06* | -0.02 | 0.11*** | -0.02 | 1.0*** | -0.94*** | -0.23*** |
| weather_Mist | 0.01 | -0.02 | -0.03 | 0.05 | -0.1*** | -0.09** | -0.04 | -0.14*** | 0.0 | 0.09** | 0.01 | -0.13*** | -0.28*** | -0.17*** | 0.43*** | 0.03 | 0.04 | -0.1*** | 0.03 | -0.94*** | 1.0*** | -0.12*** |
| weather_Rain/Snow | 0.06* | -0.03 | 0.1*** | 0.03 | -0.06 | -0.07* | 0.12*** | -0.23*** | -0.03 | 0.03 | -0.02 | -0.07* | -0.07** | -0.2*** | 0.27*** | 0.09** | -0.04 | -0.03 | -0.02 | -0.23*** | -0.12*** | 1.0*** |
| Variable | Correlation & Significance | |
|---|---|---|
| 0 | month | 0.19*** |
| 1 | holiday | -0.0 |
| 2 | day_of_week | -0.05 |
| 3 | workingday | 0.04 |
| 4 | temp | 0.52*** |
| 5 | atemp | 0.52*** |
| 6 | windspeed | -0.2*** |
| 7 | count | 1.0*** |
| 8 | temp_no | 0.43*** |
| 9 | atemp_bin_cold | -0.23*** |
| 10 | atemp_bin_mild | 0.39*** |
| 11 | atemp_bin_warm | 0.16*** |
| 12 | humidity_bin_low | -0.08** |
| 13 | humidity_bin_medium | 0.2*** |
| 14 | humidity_bin_high | -0.15*** |
| 15 | season_Fall | 0.07* |
| 16 | season_Spring | 0.1*** |
| 17 | season_Summer | 0.29*** |
| 18 | season_Winter | -0.47*** |
| 19 | weather_Clear to Cloudy | 0.22*** |
| 20 | weather_Mist | -0.14*** |
| 21 | weather_Rain/Snow | -0.23*** |
Linear regression without polynomial transformation
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
<matplotlib.axes._subplots.AxesSubplot at 0x7fe851c2a828>
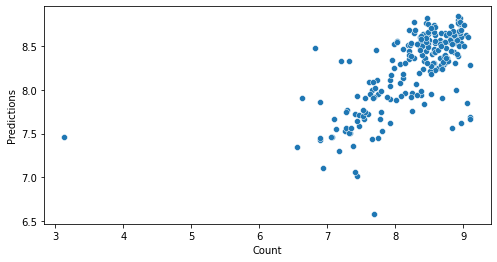
Evaluating predictions
We can evaluate the predictions using Root mean Squared Log Error (RMSLE)
R2: 44.029165944830574 %
RMSE: 0.5088707035845853
RMSLE: 0.5071272452091635
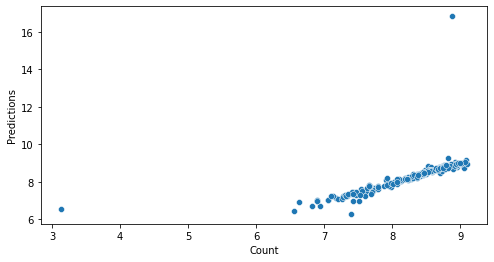
Back to polynomial transformation
Now, that we have seen that without polynomial transformation we get a RMSLE score of 0.507 lets try with the polynomial transformation.
1 month ... weather_Mist weather_Rain/Snow weather_Rain/Snow^2
0 1.0 8.0 ... 0.0 0.0
1 1.0 2.0 ... 0.0 0.0
2 1.0 6.0 ... 0.0 0.0
3 1.0 2.0 ... 0.0 0.0
4 1.0 11.0 ... 0.0 1.0
[5 rows x 276 columns]
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
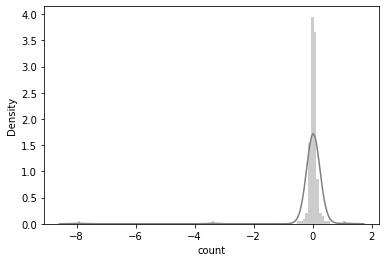
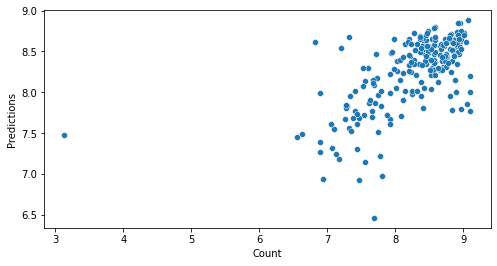
R2: 22.13254677543377 %
RMSE: 0.6002118212313721
RMSLE: 0.5991302674566322
Random forest regressor
RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion='mse',
max_depth=None, max_features='auto', max_leaf_nodes=None,
max_samples=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None, oob_score=False,
random_state=None, verbose=0, warm_start=False)
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
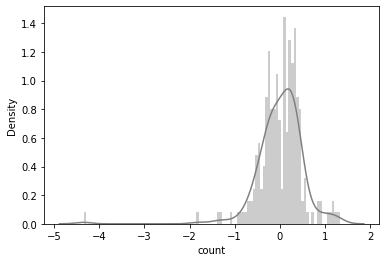
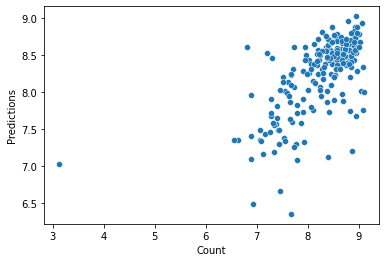
R2: 40.83093585563251 %
RMSE: 0.5232074381024822
RMSLE: 0.5214938879406389
Gradient boosting regressor
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
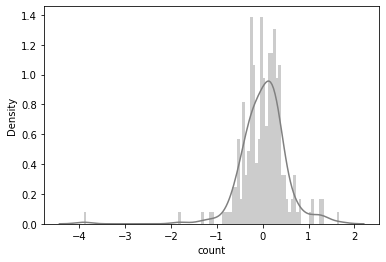
R2: 41.92546239525904 %
RMSE: 0.5183456277546589
RMSLE: 0.5167765321375696
XG Boost Regressor
[06:03:21] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
/usr/local/lib/python3.6/dist-packages/seaborn/distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).
warnings.warn(msg, FutureWarning)
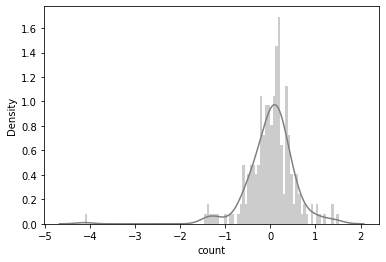
R2: 35.83080957789135 %
RMSE: 0.5448661642271247
RMSLE: 0.5432712054784864
Conclusion
The results for different models are shown in the table below. Clearly linear regression with polynomial transformation performs the best in terms of RMSE score.
| Model | R2 Score(%) | RMSE | RMSLE |
|---|---|---|---|
| Linear regression | 44.02 | 0.508 | 0.507 |
| Linear regression (polynomial) | 22.13 | 0.60 | 0.59 |
| Random forest regressor | 43.28 | 0.512 | 0.510 |
| Gradient boosting regressor | 43.44 | 51.1 | 51.0 |
| XG Boost regressor | 25.83 | 0.544 | 0.5432 |
Vivek Maskara
Senior SDE @ Micromart
I build apps, write about tech, and ship products used by thousands. Senior SDE @ Micromart.