Implementing YOLOV1 from scratch using Keras Tensorflow 2.0
This post was written using a Jupyter notebook. Convert your own with mdedit.ai's ipynb → Markdown converter.
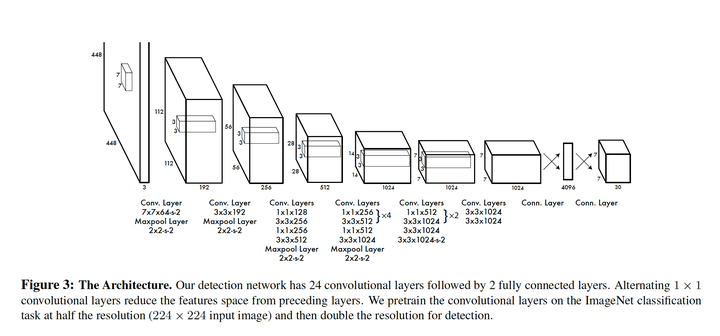
In this notebook I am going to implement YOLOV1 as described in the paper You Only Look Once. The goal is to replicate the model as described in the paper and in the process, understand the nuances of using Keras on a complex problem.
Data Preprocessing
I would be using VOC 2007 dataset as its size is manageable so it would be easy to run it using Google Colab.
First, I download and extract the dataset.
Next, we process the annotations and write the labels in a text file. A text file is easier to consume as compared to XML.
2007 train
2007 val
2007 test
Next, I am adding a function to prepare the input and the output. The input is a (448, 448, 3) image and the output is a (7, 7, 30) tensor. The output is based on S x S x (B * 5 +C).
S X S is the number of grids B is the number of bounding boxes per grid C is the number of predictions per grid
Training the model
Next, I am defining a custom generator that returns a batch of input and outputs.
The code snippet below, prepares arrays with inputs and outputs.
Next, we create instances of the generator for our training and validation sets.
(4, 448, 448, 3)
(4, 7, 7, 30)
(4, 448, 448, 3)
(4, 7, 7, 30)
Define a custom output layer
We need to reshape the output from the model so we define a custom Keras layer for it.
Defining the YOLO model.
Next, we define the model as described in the original paper.
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_120 (Conv2D) (None, 448, 448, 64) 9472
_________________________________________________________________
max_pooling2d_20 (MaxPooling (None, 224, 224, 64) 0
_________________________________________________________________
conv2d_121 (Conv2D) (None, 224, 224, 192) 110784
_________________________________________________________________
max_pooling2d_21 (MaxPooling (None, 112, 112, 192) 0
_________________________________________________________________
conv2d_122 (Conv2D) (None, 112, 112, 128) 24704
_________________________________________________________________
conv2d_123 (Conv2D) (None, 112, 112, 256) 295168
_________________________________________________________________
conv2d_124 (Conv2D) (None, 112, 112, 256) 65792
_________________________________________________________________
conv2d_125 (Conv2D) (None, 112, 112, 512) 1180160
_________________________________________________________________
max_pooling2d_22 (MaxPooling (None, 56, 56, 512) 0
_________________________________________________________________
conv2d_126 (Conv2D) (None, 56, 56, 256) 131328
_________________________________________________________________
conv2d_127 (Conv2D) (None, 56, 56, 512) 1180160
_________________________________________________________________
conv2d_128 (Conv2D) (None, 56, 56, 256) 131328
_________________________________________________________________
conv2d_129 (Conv2D) (None, 56, 56, 512) 1180160
_________________________________________________________________
conv2d_130 (Conv2D) (None, 56, 56, 256) 131328
_________________________________________________________________
conv2d_131 (Conv2D) (None, 56, 56, 512) 1180160
_________________________________________________________________
conv2d_132 (Conv2D) (None, 56, 56, 256) 131328
_________________________________________________________________
conv2d_133 (Conv2D) (None, 56, 56, 512) 1180160
_________________________________________________________________
conv2d_134 (Conv2D) (None, 56, 56, 512) 262656
_________________________________________________________________
conv2d_135 (Conv2D) (None, 56, 56, 1024) 4719616
_________________________________________________________________
max_pooling2d_23 (MaxPooling (None, 28, 28, 1024) 0
_________________________________________________________________
conv2d_136 (Conv2D) (None, 28, 28, 512) 524800
_________________________________________________________________
conv2d_137 (Conv2D) (None, 28, 28, 1024) 4719616
_________________________________________________________________
conv2d_138 (Conv2D) (None, 28, 28, 512) 524800
_________________________________________________________________
conv2d_139 (Conv2D) (None, 28, 28, 1024) 4719616
_________________________________________________________________
conv2d_140 (Conv2D) (None, 28, 28, 1024) 9438208
_________________________________________________________________
conv2d_141 (Conv2D) (None, 14, 14, 1024) 9438208
_________________________________________________________________
conv2d_142 (Conv2D) (None, 12, 12, 1024) 9438208
_________________________________________________________________
conv2d_143 (Conv2D) (None, 10, 10, 1024) 9438208
_________________________________________________________________
flatten_5 (Flatten) (None, 102400) 0
_________________________________________________________________
dense_15 (Dense) (None, 512) 52429312
_________________________________________________________________
dense_16 (Dense) (None, 1024) 525312
_________________________________________________________________
dropout_5 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_17 (Dense) (None, 1470) 1506750
_________________________________________________________________
yolo__reshape_10 (Yolo_Resha (None, 7, 7, 30) 0
=================================================================
Total params: 114,617,342
Trainable params: 114,617,342
Non-trainable params: 0
_________________________________________________________________
Define a custom learning rate scheduler
The paper uses different learning rates for different epochs. So we define a custom Callback function for the learning rate.
Define the loss function
Next, we would be defining a custom loss function to be used in the model. Take a look at this blog post to understand more about the loss function used in YOLO.
I understood the loss function but didn’t implement it on my own. I took the implementation as it is from this Github repo.
Add a callback for saving the weights
Next, I define a callback to keep saving the best weights.
Compile the model
Finally, I compile the model using the custom loss function that was defined above.
Train the model
Now that we have everything setup, we will call model.fit to train the model for 135 epochs.
Epoch 00000: Learning rate is 0.0100.
Epoch 1/135
625/625 [==============================] - 195s 311ms/step - loss: 88.0331 - val_loss: 245.3397
Epoch 00001: Learning rate is 0.0100.
Epoch 2/135
625/625 [==============================] - 194s 310ms/step - loss: 140.9500 - val_loss: 116.6240
Epoch 00002: Learning rate is 0.0100.
Epoch 3/135
625/625 [==============================] - 194s 310ms/step - loss: 114.1760 - val_loss: 113.2524
Epoch 00003: Learning rate is 0.0100.
Epoch 4/135
625/625 [==============================] - 194s 310ms/step - loss: 113.0043 - val_loss: 112.8592
Epoch 00004: Learning rate is 0.0100.
Epoch 5/135
625/625 [==============================] - 189s 303ms/step - loss: 112.9847 - val_loss: 113.3475
Epoch 00005: Learning rate is 0.0100.
Epoch 6/135
625/625 [==============================] - 194s 310ms/step - loss: 113.0094 - val_loss: 112.7520
Epoch 00006: Learning rate is 0.0100.
Epoch 7/135
625/625 [==============================] - 194s 310ms/step - loss: 71.0617 - val_loss: 61.3470
Conclusion
It was a good exercise to implement YOLO V1 from scratch and understand various nuances of writing a model from scratch. This implementation won’t achieve the same accuracy as what was described in the paper since we have skipped the pretraining step.
Vivek Maskara
Senior SDE @ Micromart
I build apps, write about tech, and ship products used by thousands. Senior SDE @ Micromart.